最近的AIGC圈子是非常热闹。
前段时间刚看到OpenAI使用自回归模型端了扩散模型在“图像生成”领域的老窝,然后立马又关注到扩散模型成为了“文本生成”领域的新贵()。真的是神仙打架,有来有往。

最近的一篇论文《LLaDA: Learning Latent Diffusion Models for Autoregressive Text Generation》,作者认为扩散模型可以成为自回归模型之外的可行选择。
本文主要分为三个部分:
- 核心论点:扩散模型可以成为自回归模型之外的可行选择
- 论据支持:LLaDA 的全面实验验证
- 方法创新:掩码扩散框架的设计
核心论点:扩散模型可以成为自回归模型之外的可行选择
主要挑战:
当前大语言模型(LLMs)普遍采用自回归模型(Autoregressive Models, ARMs),通过逐词预测实现文本生成。但作者认为,自回归结构并非LLMs能力的唯一根源,其本质源于生成建模原则(如最大似然估计),而扩散模型(Diffusion Models)同样能实现类似甚至更优的表现。
核心主张:
- 生成建模原则是关键:LLMs的核心能力(如上下文学习、指令跟随)源于对数据分布的建模,而非自回归结构本身。
- 自回归模型的局限性:逐词生成导致计算效率低、难以处理逆向推理任务(如“逆向诅咒”)。
- 扩散模型的潜力:通过掩码扩散建模双向依赖关系,可实现更灵活、鲁棒的生成。

论据支持:LLaDA 的全面实验验证
1. 性能对标主流LLMs
• 基准测试:在MMLU、GSM8K、代码生成(HumanEval)等15项任务中,8B参数的LLaDA与LLaMA3 8B表现相当,部分任务(如中文理解CMMLU)显著优于LLaMA2 7B。
• 逆向任务突破:在“逆向诗歌补全”任务中,LLaDA以42.4%准确率超过GPT-4o(34.3%),证明其双向建模优势。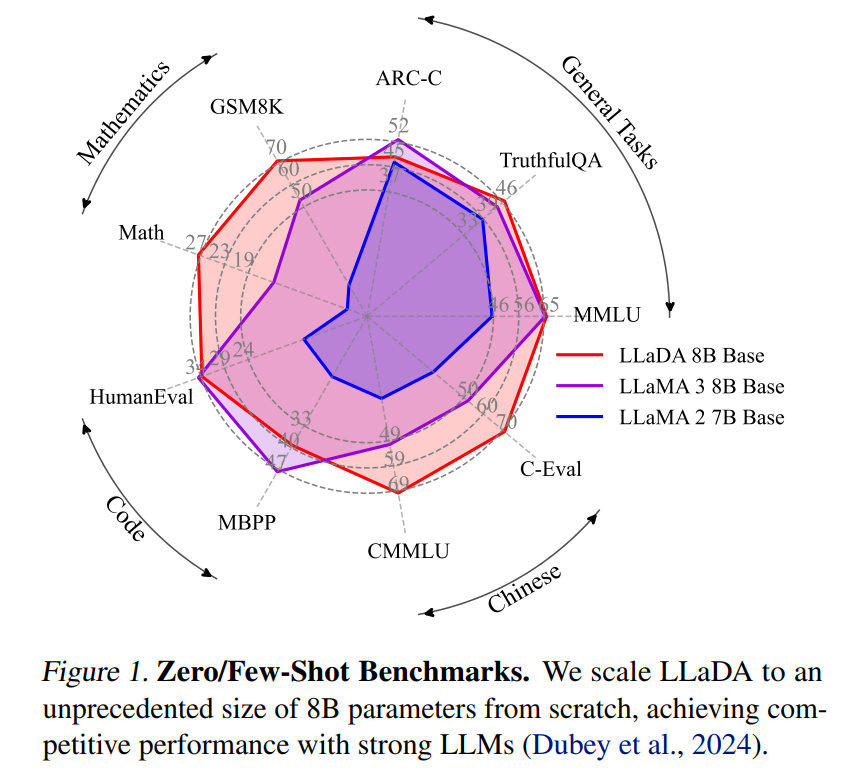
2. 可扩展性验证
• 从1B到8B参数,LLaDA的训练损失随计算量(FLOPs)稳定下降,与自回归模型基线趋势一致,验证扩散模型在大规模训练中的可行性。
3. 指令跟随与多轮对话
• 经过监督微调(SFT),LLaDA展现出流畅的多语言对话能力(如中英德翻译),生成文本连贯且符合上下文逻辑。
方法创新:掩码扩散框架的设计
1. 前向与反向过程
• 前向掩码:随机按时间步长 ( t \in [0,1] ) 对输入序列逐步掩码(如t=0为完整文本,t=1全掩码)。
• 反向生成:训练Transformer预测被掩码的token,通过多步迭代重建完整文本(类似图像扩散的去噪过程)。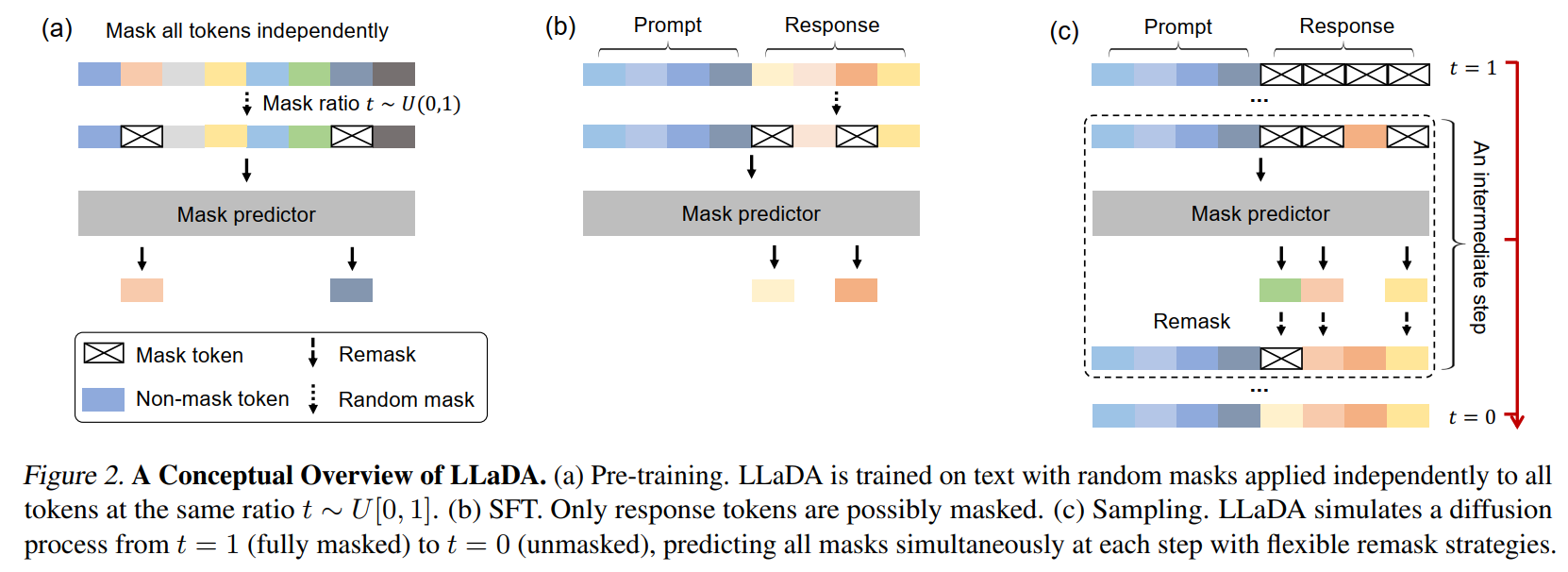
2. 训练目标
• 优化对数似然上界(式3),仅对掩码位置计算交叉熵损失:
3. 推理优化策略
• 动态长度训练:1%的训练数据采用随机长度(1-4096 token),提升模型对可变长度输入的适应性。
• 半自回归生成:将输出分块生成,块内并行预测掩码,兼顾效率与质量。
• 低置信度重掩码:在反向过程中优先重掩码低置信度预测,加速收敛。
核心贡献与意义
1. 理论突破
• 首次验证扩散模型的LLM潜力:以80亿参数规模证明扩散模型在语言任务中可媲美主流自回归模型。
• 统一视角:揭示掩码扩散与任意顺序自回归模型(AO-ARM)的等价性(式15),为双向建模提供理论支撑。
2. 工程实践
• 高效训练框架:提出动态掩码策略、Warmup-Stable-Decay学习率调度等方法,实现2.3万亿token的高效预训练(0.13万H800 GPU小时)。
• 开源生态:发布代码与模型权重(https://ml-gsai.github.io/LLaDA-demo/),推动非自回归LLM研究。
3. 应用前景
• 解决逆向诅咒:在需要双向推理的任务(如诗歌补全、逻辑回溯)中表现突出。
• 更灵活生成:支持多步采样调控生成质量,为可控文本生成提供新思路。
局限与未来方向
• 计算成本:扩散模型推理需多步迭代,实时性弱于自回归模型。
• 扩展潜力:尚未探索强化学习对齐、多模态融合等后续优化。
• 架构优化:可设计更适合扩散模型的注意力机制与位置编码。
后续
商业化应用:2025年2月26日,Inception Labs发布了Mercury Coder,宣称是首个商业化规模的dLLM。其核心创新在于并行生成机制,显著提升效率,在NVIDIA H100上生成速度达1000 tokens/秒,比传统自回归模型快5-20倍,且运行成本降低5-10倍。Inception Labs由斯坦福教授Stefano Ermon等创立,其团队包括MDLM论文作者Volodymyr Kuleshov,显示出研究与商业化的紧密联系。

近期SOTA:香港大学与华为诺亚方舟实验室推出的Dream 7B(扩散推理模型),通过扩散架构创新+AR知识迁移,证明了扩散模型在大规模语言任务中的竞争力。其规划能力优势和推理灵活性为智能体、代码生成等场景提供新可能。
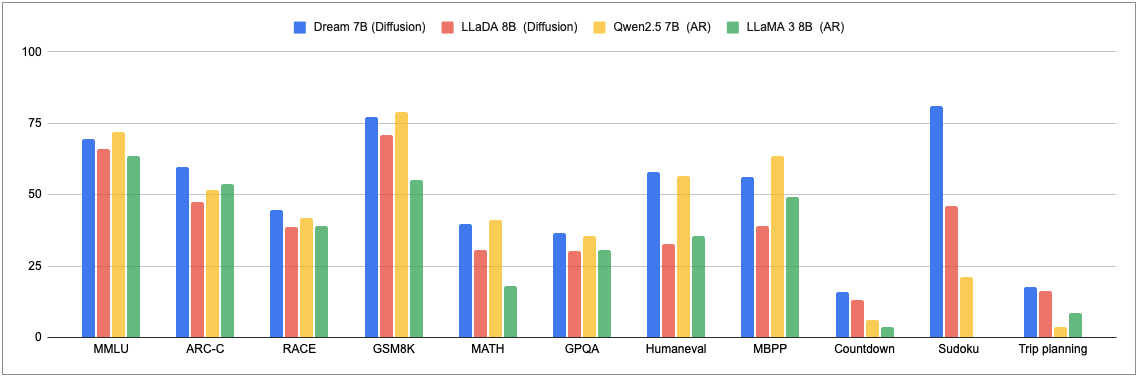
一般任务、数学任务、编码任务和规划任务的语言模型比较
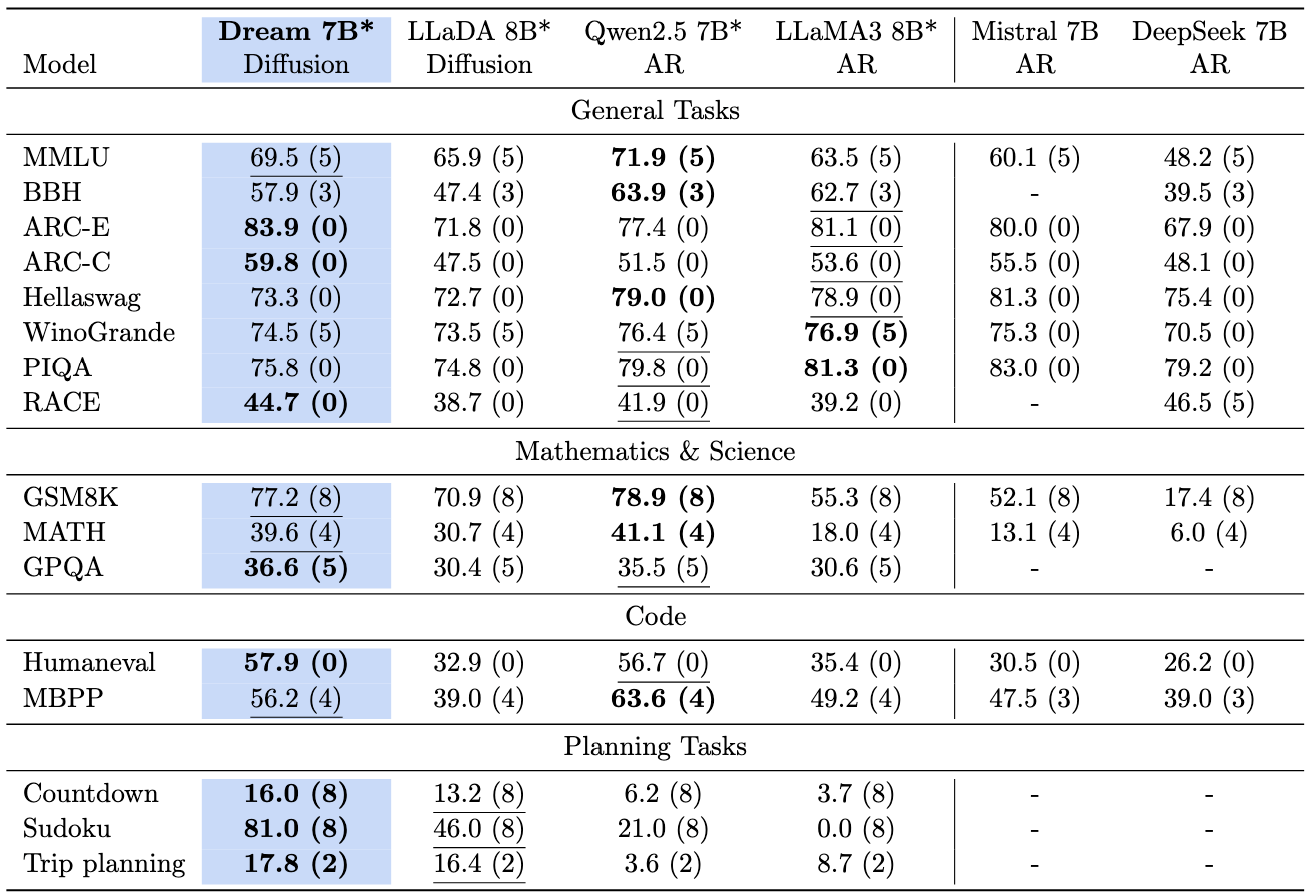
语言模型在标准评估基准上的比较